
Além do Monitoramento de API
Atualmente é bastante difícil encontrar uma aplicação cujo fluxo de dados não dependa de sistemas externos, como um banco de dados, filas ou cache. Poderíamos até incluir um serviço de API na mistura, caso seja um serviço de terceiros. E tudo isso é passível de falhas, tanto de software como de hardware, que podem causar problemas sérios para o sistema ou afetar sua usabilidade. Alguns usuários poderiam parar de utilizar a API ou o sistema por motivos de baixa performance ou porque acontecem muitos erros não resolvidos.
Monitoramento nos permite visualizar como a aplicação se comporta com a quantidade de usuários ativos ou até para uma quantidade maior. Além disso, ele nos permite medir e manter um certo nível de aceitação do serviço, possibilitando assim uma maior estabilidade e resiliência na aplicação.
Existem algumas ferramentas para monitorar APIs, como o Datadog, New Relic, Kibana ou AWS CloudWatch, mas nesse artigo não iremos focar muito nelas, pois cada uma possui uma peculiaridade. Entretanto, as métricas e os conceitos permanecem os mesmos, e podemos utilizá-los em qualquer ferramenta.
Para um bom monitoramento, é preciso se preocupar com alguns conceitos, como confiabilidade, escalabilidade e capacidade de manutenção.
- Confiablidade define-se como a capacidade de o sistema funcionar corretamente apesar de algumas adversidades, como uma falha de dados ou erro de execução.
- Escalabilidade envolve manter um nível de performance com o crescimento do sistema, como crescimento de tráfego, volume de dados e complexidade.
- Capacidade de manutenção refere-se a um sistema em que várias pessoas conseguem realizar correções ou adicionar novas funcionalidades de forma produtiva, sem que se gaste muito tempo, evitando a criação de débito técnico.
Esses conceitos merecem um estudo mais aprofundado, talvez até um artigo dedicado para cada um, mas aqui iremos mostrar apenas a correlação entre eles. Por exemplo, de nada adianta uma API com um tempo de execução baixíssimo, mas que a frequência de erro é altíssima. Outro exemplo é uma API que tem várias maneiras de mitigação de erro, porém com tempo de criação de uma nova funcionalidade bastante longo, tendo assim uma capacidade de manutenção baixa, dificultando a estabilidade do nível de performance quando a demanda cresce ou quando for preciso realizar uma alteração no negócio.
Com o crescimento de tráfego em uma API, alguns indicadores podem ser notados com mais facilidade, como usabilidade e escalabilidade, que podem ser observados através do tempo de resposta. Isso porque a escalabilidade é afetada por causa de alta demanda, aumentando assim o processamento da API e, consequentemente, o tempo de resposta. Já a usabilidade é afetada porque o serviço torna-se mais demorado. É importante também notar a diferença entre tempo de resposta e latência. O tempo de resposta é o tempo que demora para o usuário enviar e receber a mensagem, contando o tempo de processamento. Latência é o tempo que a mensagem passa no caminho e independe do processamento da requisição, com o tempo podendo ser afetado por problemas de conexão. Sendo assim, iremos focar em tempo de resposta, já que problemas de conexão estão fora do nosso controle.
Mas como melhorar?
Para isso, precisaríamos responder algumas perguntas. Utilizando o exemplo do crescimento de tráfego, podemos perguntar: quanto de recurso teríamos que aumentar para que a performance permanecesse a mesma? Como a performance seria afetada se os recursos fossem os mesmos, mas a demanda aumentasse? Para ter as respostas, precisaríamos de números e, para isso, de monitoramento.
O monitoramento pode ser algumas vezes uma tarefa complexa, pois pode envolver dependência de outros serviços, como um banco de dados, API externa ou cache, como é mostrado na imagem abaixo. Esses serviços influenciam no tempo de resposta, pois a requisição só estará completa quando todas as respostas das dependências e o processamento da API foram finalizados. Além disso, cada vez que enviamos uma requisição, recebemos um tempo de resposta um pouco diferente, devido à rede, ao sistema ou a outros serviços. Por esse motivo, a métrica de tempo de resposta deve ser um conjunto de valores coletados em um intervalo de tempo, não apenas um número.
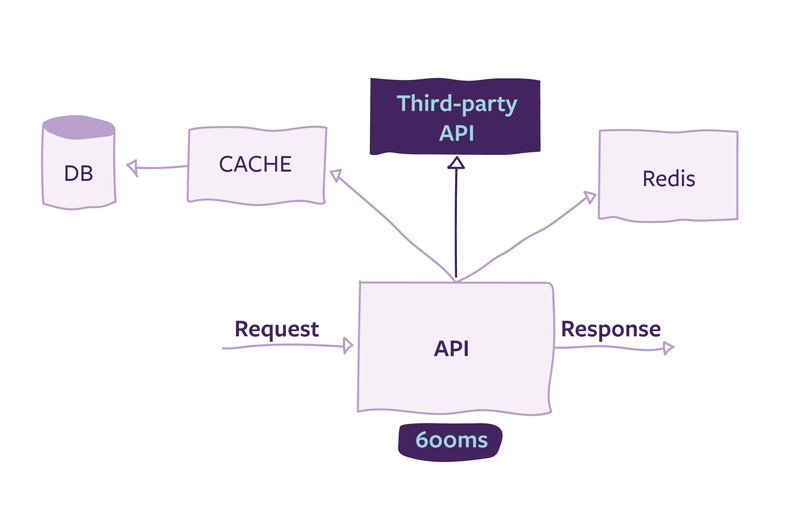
Uma vez que temos os valores do tempo de resposta, geralmente a primeira coisa que se pensa é em descobrir o tempo médio de uma requisição. Entretanto, apesar de ser um número que agrega valor à compreensão do comportamento do sistema, ele esconde os usuários que estão nos polos, ou seja, os usuários que tiveram respostas muito rápidas ou muito lentas.
Podemos utilizar percentiles para tentar resolver esse problema. Se ordenarmos o tempo de resposta de forma ascendente, o valor que está exatamente na metade do conjunto é a mediana. A mediana também é conhecida como 50th percentile, ou p50, e indica qual o tempo de resposta que geralmente os usuários possuem. Para sabermos como os usuários que têm maior tempo de resposta se comportam, podemos procurar pelos usuários que possuem tempo de resposta maior que 95% ou 99% dos demais.
Um alto tempo de resposta pode ter causa tanto no cliente como na aplicação. O cliente poderia ter uma falha de conexão ou a aplicação pode ter feito uma consulta não otimizada. No contexto de uma aplicação web, os usuários possuem entradas no banco e cada usuário possui uma quantidade diferente, por exemplo, de livros favoritos. Os usuários que mais utilizam a aplicação geralmente possuem mais entradas no banco, realizam mais compras ou possuem mais livros cadastrados. Por esse motivo, as requisições realizadas por esses usuários podem demorar mais que as de um usuário comum, podendo assim serem encontrados em altos percentiles.
Ainda no contexto da aplicação web, se quisermos realizar uma otimização, esses usuários são fortes candidatos para serem focados, pois as melhorias realizadas neles são propagadas para os outros percentiles. Só precisamos ter cuidado para não escolher percentiles muito específicos, como os 99,99%, já que a manutenção feita para eles pode ser custosa demais e não vale muito a pena, porque estes podem ser casos que não acontecem com tanta frequência. Lembrando que, dependendo da estratégia de negócio da aplicação, talvez não seja tão importante utilizar tempo para otimização.
Como ir além de monitorar tempo de resposta?
Lembrando que a API geralmente é uma composição de vários serviços, o ideal seria também monitorar tais serviços, já que eles vão afetar diretamente a resposta da nossa API. Para isso, uma verificação periódica nesses serviços é essencial, não apenas uma checagem se a resposta é 200, mas verificar o conteúdo da resposta. O conteúdo é importante porque não temos controle de alterações realizadas por terceiros, e por isso precisamos definir um “contrato” de resposta, em métodos idempotentes (em que a resposta será a mesma independentemente de quantas requisições forem enviadas).
Além disso, trazendo para a nossa API, podemos criar um rastreamento de atividades, em que, para cada requisição, conseguiremos monitorar se a API está se comportando da maneira que queremos e não está indo por caminhos indesejáveis. Utilizando esse rastreamento, é preciso também anonimizar as informações, para proteger os dados dos usuários e evitar maiores problemas em caso de vazamento.
Mas como manter essas melhorias?
Como estamos sempre criando novas funcionalidades ou realizando refatorações no código. Não temos certeza de como a performance vai ser afeta. Apesar de termos testes para validar a funcionalidade, o contrato de performance não é tão explicito. Para isso, utilizamos SLA (Service Level Agreements), no qual especificamos o tempo de resposta para cada percentile. Por exemplo, para o p50, podemos ter pelo menos 200ms, enquanto para o p90, a resposta pode demorar até 900ms. É bom também ter em mente que quando realizamos esses testes, as requisições devem ser enviadas de maneira que seja o mais próxima possível do ambiente de produção, com alta concorrência ou com consultas mais pesadas.
Falamos de muita coisa teórica e bem específica para tempo de resposta, mas como isso afeta no negócio? Existe uma relação direta entre melhorar o desempenho e conseguir mais clientes na aplicação? A resposta é talvez. Melhoria de performance não é tudo que vai influenciar no sucesso da aplicação, usabilidade e interesse são outros exemplos de indicadores.
Quando melhoramos a performance da aplicação, em um site de e-commerce, por exemplo, em que o tempo para realizar uma compra diminui ou a navegação fica mais fluida, o usuário final fica mais satisfeito, podendo até realizar mais compras. Sabemos como uma página lenta pode ser frustrante e deixamos de utilizar depois de alguns minutos, ou até segundos, gerando também uma imagem ruim do serviço.
Referências:
- Tyler Treat (2015), Everything You Know About Latency Is Wrong
- Kleppmann, M. (2017). Designing Data-Intensive Applications. Beijing: O'Reilly. ISBN: 978-1-4493-7332-0
- Patrick Poulin (2020), API Monitoring: A False Sense of Security
