Graph Databases: Discutindo o Relacionamento dos seus Dados com Python
Você já parou pra pensar quantos relacionamentos você tem na sua vida online? Cada amigo no Facebook, cada página curtida, cada conexão no LinkedIn ou cada perfil seguido no Twitter é um novo relacionamento não só pessoal, como virtual também. Só no Brasil, temos 160 milhões de usuários do Facebook. Como representar e manipular todas essas relações?
Suponha que temos um esquema de dados similar ao Facebook, onde um usuário pode ser amigo de outro usuário ou curtir uma página. Vamos tentar estruturar esses dados em tabelas, como em um Banco de Dados Relacional.
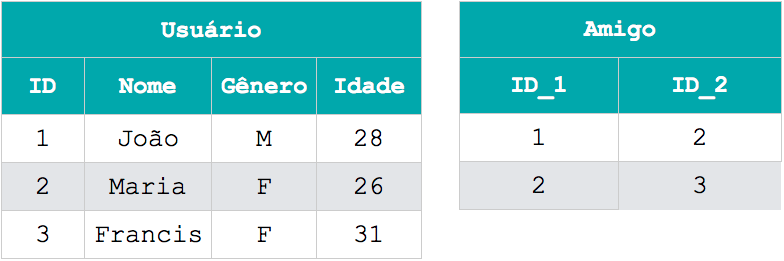
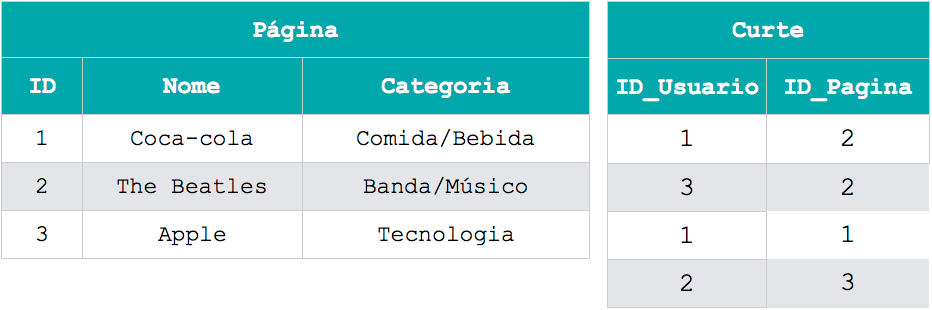
Para armazenar o relacionamento entre usuários e entre usuários e páginas, foi necessário criar 2 tabelas que conectam os identificadores dos usuários e das páginas. Para desenvolvedores que não estão acostumados a trabalhar com tabelas, descobrir quais páginas o usuário de nome João curte não é uma ação tão natural assim.
A dificuldade de visualizar os relacionamentos entre as entidades em um banco relacional é um ótimo motivo para introduzir o conceito de grafo. Grafo é uma estrutura de dados formada por um conjunto de vértices V e um conjunto E de pares de vértices, chamados de arestas. Pode ser representado graficamente (onde os vértices são representados por círculos e arestas representadas por linhas) ou matematicamente na forma G = (V, E). É uma forma simples, intuitiva e gráfica de mostrar a relação entre objetos. Dado o conceito de grafo, é possível representar o mesmo cenário apresentado anteriormente em uma estrutura diferente como mostra a imagem abaixo.
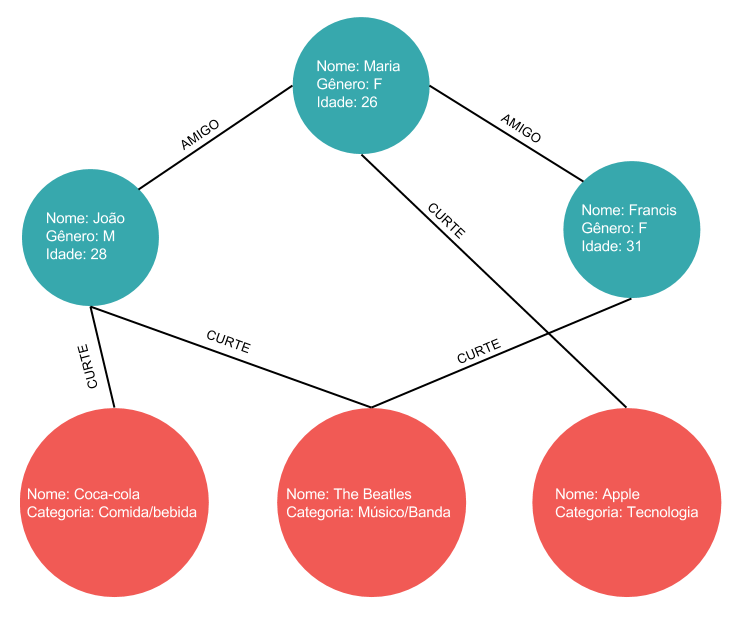
Com essa representação gráfica, fica mais intuitivo saber quem é amigo de quem e quais páginas um determinado usuário curte. Da mesma forma, é possível armazenar os dados e o relacionamento entre eles usando um Banco de Dados em Grafo.
Banco de Dados em Grafo
Banco de Dados em Grafo é um sistema que armazena dados em estruturas de grafo e permite consultas mais semânticas, recuperando dados relacionados de forma direta. Além de melhorar a representação de relacionamentos, os Banco de Dados em Grafo também permitem fazer análises mais elaboradas dos dados, como detecção de comunidades, reconhecimento de padrões e medidas de centralidade. Outra vantagem dos BDs em grafo é a flexibilidade do modelo dos dados. Enquanto nos bancos relacionais é preciso criar ou alterar tabelas existentes para adicionar novos tipos de dados, em um DB em grafo é possível adicionar novos tipos de vértices e arestas a um grafo existente sem precisar fazer modificações do esquema de dados. A imagem abaixo mostra como ficaria o grafo, caso o conceito de “Grupos de Discussão” fosse adicionado à rede social do exemplo.
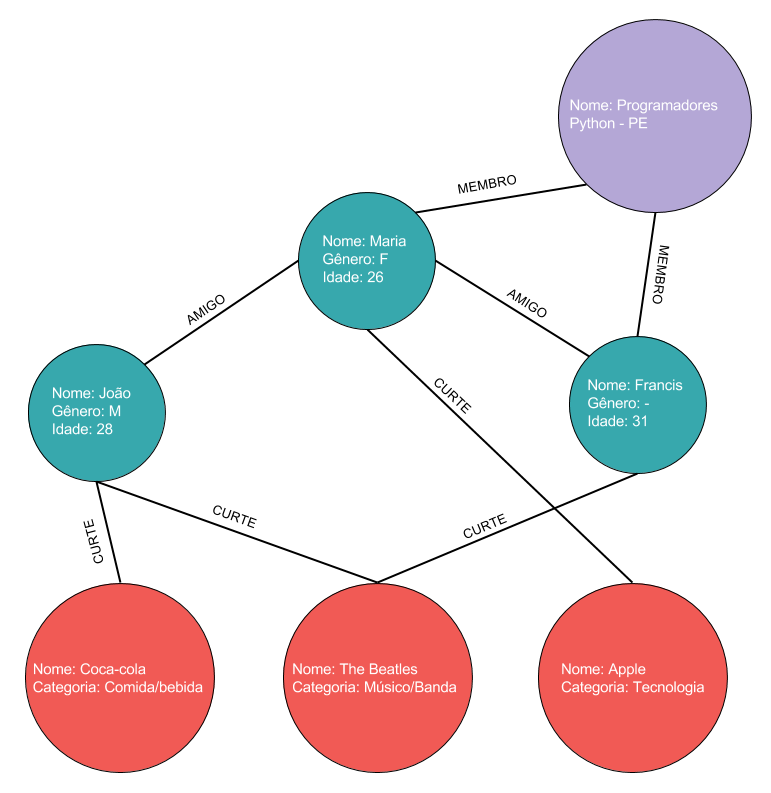
Os BDs em grafo mais modernos também oferecem vantagem no quesito performance, uma vez que estes utilizam mecanismos de armazenamento de dados baseados em sistemas NoSQL. Assim, esses bancos se tornam escaláveis e podem ser distribuídos em vários núcleos de processamento através da nuvem. Das implementações mais recentes dos Bancos de Dados em Grafo, as mais populares são Neo4J, OrientDB e TitanDB.
Neo4J
O Neo4J é o primeiro e mais popular banco de dados em grafo nativo de acordo com o site DB Engines. É um projeto open source implementado em Java e possui uma linguagem de consulta própria chamada Cypher. Possui uma comunidade bem ativa no Github e Stackoverflow, além de blog posts e e-books disponíveis. O acesso aos dados no banco pode ser feito usando uma API em Java ou usando uma API RESTful.
Exemplo — API REST
O acesso à API REST pode ser feito através do Neo4J browser, submetendo consultas Cypher. Abaixo, são listados exemplos de como criar um novo vértice, criar um novo relacionamento e realizar uma consulta.
Criar Vértice
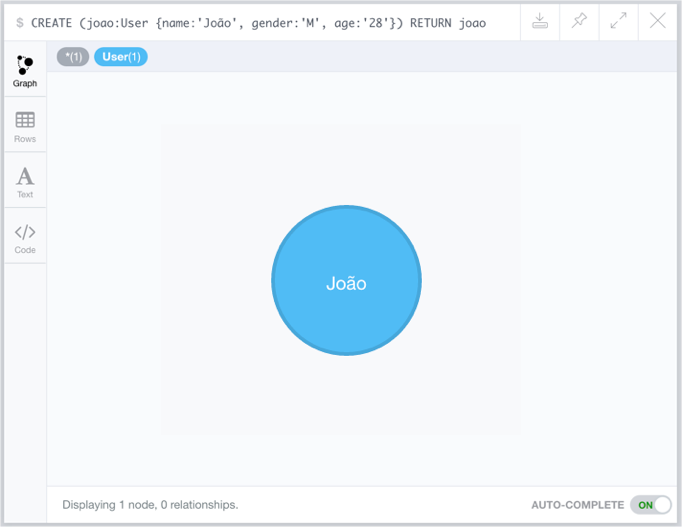
O comando Cypher mostrado abaixo cria um novo vértice no banco. O nome que vem antes dos dois pontos :, nesse exemplo, joao é o alias atribuído ao vértice e é apenas usado como referência na consulta que está sendo submetida, ou seja, não é armazenado no banco. Já o nome User indica qual a label (ou tipo) do vértice que está sendo criado. Os atributos do vértice são passados dentro das chaves ‘{’.
Uma vez que esse comando Cypher é submetido no Neo4J browser, o retorno pode ser visto em forma gráfica (com o desenho do grafo) ou no formato JSON retornado pela API. Como o comando apenas pede o retorno do vértice do usuário criado, apenas um vértice é mostrado.
O retorno JSON provido pela API REST mostra, dentre outras coisas, o objeto graph que contém uma lista de vértices e uma lista de relacionamentos. Cada vértice possui um id, uma lista de labels e o conjunto de propriedades. Como esse vértice é o primeiro a ser criado, a lista de vértices possui um único item.
Criar Relacionamento
Considere que 2 vértices já estejam criados no banco. O comando Cypher abaixo cria um relacionamento entre dois usuários existentes. Os relacionamentos também possuem um label (ou tipo) e podem ser referenciados usando um alias. Tanto para a criação ou para a consulta de relacionamentos, é usada a notação da seta -[REL]->, onde a ponta indica para qual direção do relacionamento. Caso o relacionamento seja bidirecional, a notação usada é -[REL]-, sem a seta.
Note que antes de criar o relacionamento, é necessário recuperar os vértices que serão conectados. Nesse exemplo, foram recuperados os vértices do usuário João e da usuária Maria de acordo com seus nomes e, em seguida, os mesmos foram conectados através do relacionamento do tipo FRIENDS_WITH com o alias f. O retorno desse comando mostra os usuários recuperados e o novo relacionamento criado entre eles.
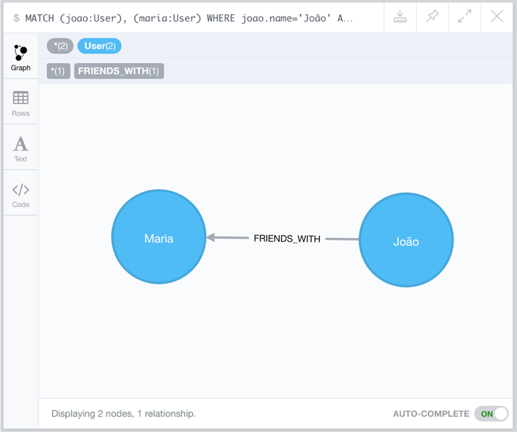
O objeto graph do retorno JSON da API agora mostra um item na lista de relacionamentos. O relacionamento possui um id, o tipo dele, o vértice inicial, o vértice final e um possível conjunto de propriedades. Dessa forma, seria possível, por exemplo, armazenar a data de criação do relacionamento (a data de quando João se tornou amigo de Maria).
Consultar o Grafo
Sabendo como criar vértices e relacionamentos, é possível armazenar no banco os dados do cenário apresentado no início deste post.
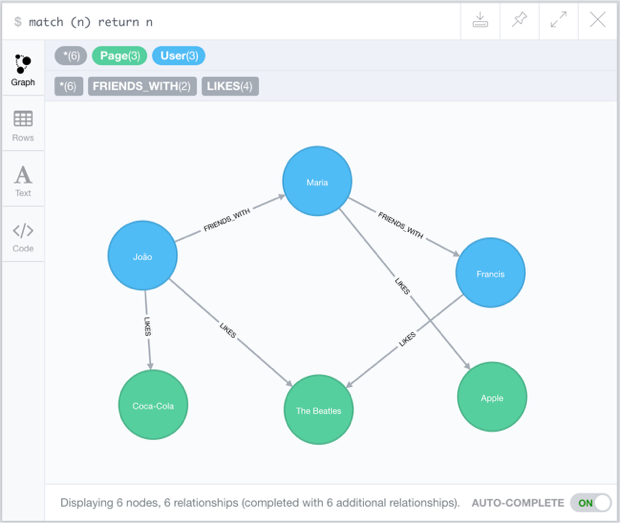
Para saber quais páginas o usuário João curte, pode-se utilizar a consulta abaixo. Essa consulta irá retornar um subgrafo do grafo original do banco, mostrando os vértices correspondentes às páginas que se relacionam com o vértice do usuário João através de um relacionamento do tipo LIKES.
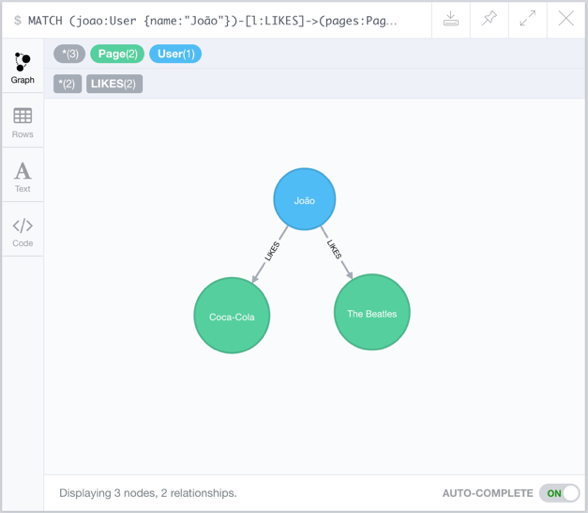
Para a consulta submetida, a API REST retorna um objeto data que contém todas as linhas que respondem à consulta. Nesse exemplo, são retornadas duas linhas e três colunas: as propriedades do usuário João, as propriedades do relacionamento LIKES e as propriedades das páginas que João curte, nessa ordem.
Exemplo — Python
Além de acessar o banco através da API REST e de uma API Java, também é possível integrar o Neo4J com uma aplicação Python usando o módulo Py2Neo. Este módulo suporta Python 2 e 3 e garante suporte para distribuições CPython. Dessa forma, é possível recriar os comandos em Cypher vistos anteriormente usando Py2Neo.
Criar Vértices e Relacionamentos
Para acessar o banco, utiliza-se a classe Graph do módulo Py2Neo, passando a senha de acesso ao Neo4J como parâmetro. A partir do objeto do tipo Graph, pode-se iniciar uma nova transação e realizar a criação de vértices e relacionamentos, gravando essas essas ações no banco uma única vez.
No exemplo acima, os vértices representando os usuários João e Maria são criados inicialmente, e em seguida o relacionamento que representa a informação que João é amigo de Maria é criado. Finalmente, é dado o commit na transação para submeter as alterações no Neo4J.
Fazer uma consulta
Py2Neo permite a execução de consultas escritas em Cypher usando a função run do objeto Graph. Além disso, o módulo também provê alguns métodos que facilitam a realização de consultas. O exemplo abaixo mostra como a consulta para recuperar as páginas que o usuário João curte pode ser feita usando Py2Neo.
Inicialmente, é necessário recuperar o vértice do usuário João usando o objeto do tipo NodeSelector e executar a função select, passando como parâmetro o tipo de vértice e qual condição ele deve obedecer. Essa função retorna uma lista de vértices que obedecem à condição. Em seguida, é utilizada a função match para recuperar todos os relacionamentos que obedecem às condições passadas: vértice inicial do usuário João e os relacionamentos do tipo LIKES. Essa função retorna uma lista de relacionamentos e, assim, é possível imprimir os atributos dos vértices finais desses relacionamentos dentro de um loop. O resultado obtido é mostrado abaixo.
>>>
(e0f611c:Page {category:"Músico/Banda",name:"The Beatles"})
(ac6964f:Page {category:"Comida/Bebida",name:"Coca-Cola"})
Comparando os BDs em Grafo
Além do Neo4j, existem outros bancos de dados em grafos que estão na lista dos mais populares de acordo com o site DB Engine.
O OrientDB é um banco de dados NoSQL Multi-Model, ou seja, armazena dados na forma de documentos, conjuntos de chave-valor, objetos, grafos, entre outros. Também é implementado em Java, mas ao contrário do Neo4J, usa SQL estendido com operadores para manipular grafos. O OrientDB também permite a criação de um esquema pré-definido para os dados, além da definição de tipos complexos, como data, decimais e objetos binários (BLOB).
Já o Titan DB é um banco de dados em grafo nativo implementado em Java. Para estabelecer a comunicação com o disco, o Titan pode ser linkado ao Cassandra, HBase ou BerkeleyDB, ficando a cargo do usuário escolher qual sistema de armazenamento de dados é mais adequado à aplicação. O acesso ao Titan (criação de vértices, arestas e consultas) pode ser feito através de uma API Java ou de um servidor que aceita consultas escritas em Gremlin.
Comparando Consultas
Para comparar a linguagem de consulta dos BDs em grafo, a mesma consulta (quais páginas o usuário João curte) foi escrita usando Cypher (Neo4J), SQL Expandido (OrientDB) e Gremlin (TitanDB).
Comparando Performance
Uma das tarefas básicas ao manipular bancos de dados em geral é recuperar uma instância armazenada dado seu ID. Esse teste de performance calcula a média de tempo para recuperar um vértice pelo seu ID, em um grafo com 500.000 vértices e 4 clientes realizando essa operação 200 vezes. O cálculo foi feito usando Neo4J, OrientDB e TitanDB usando Cassandra como backend.
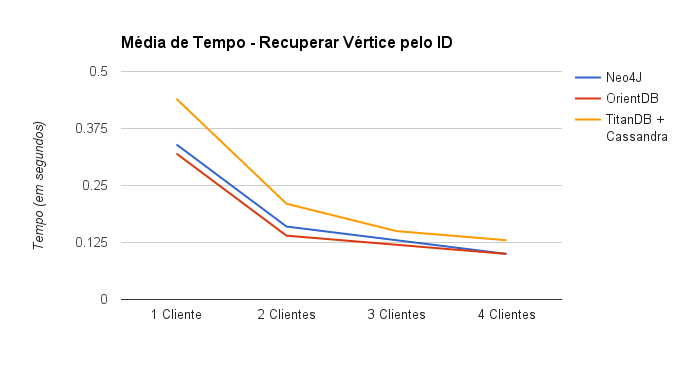
De acordo com o gráfico acima, temos que Neo4J and OrientDB possuem performances parecidas, sendo Neo4J um pouco mais rápido, em média, para recuperar um vértice dado seu ID. Já o TitanDB usado junto com Cassandra como backend, tem uma performance ruim em comparação aos demais. Contudo, TitanDB pode ser conectado através de adaptadores a outros backends, que podem melhorar a performance para essa tarefa.
Outra preocupação comum para os desenvolvedores é a quantidade de memória consumida pelo banco de dados. Nesse teste, um grafo com 32 mil vértices e 256 mil arestas foi carregado no Neo4J, OrientDB e TitanDB, e a quantidade de memória utilizada por cada banco de dados foi medida.
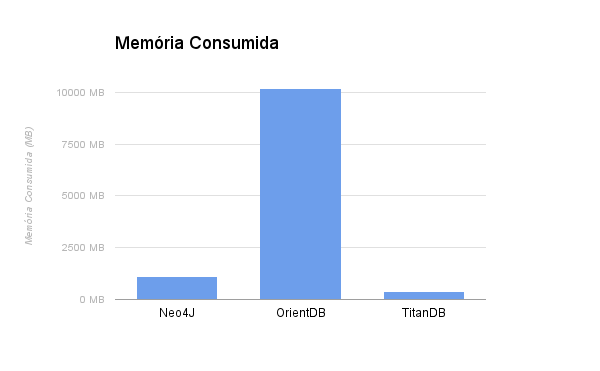
A partir do gráfico, podemos perceber que OrientDB é o que consome a maior quantidade de memória, chegando a 10.156 MB. Já TitanDB é o que consome menos memória, precisando de apenas 388 MB para armazenar o grafo.
Comparando Neo4J com Banco Relacional
É possível perceber a diferença entre os bancos relacionais e os bancos em grafo no que diz respeito à recuperação de informação, ao comparar como a mesma consulta é escrita para cada sistema. Considere uma consulta que retorna todos os usuários que curtem a página com o nome “The Beatles”.
É possível perceber que a consulta SQL é mais verborrágica que a consulta escrita em Cypher (Linguagem de Consulta nativa do Neo4j). Em bancos relacionais, é preciso realizar operações de join entre as tabelas para encontrar os dados que possuem algum tipo de relacionamento. Já nos bancos de dados em grafo, o relacionamento entre os dados pode ser explicitado na consulta, permitindo a recuperação da informação de forma mais direta.
Comparando Performance
Bancos de Dados Relacionais e de Grafo atendem a propósitos diferentes de acordo com a aplicação. Caso a aplicação necessite representar e acessar os dados baseando-se no relacionamento entre eles, o Banco de Dados de Grafo é o mais recomendado. Mas se a parte de interesse da aplicação é apenas a informação armazenada na entidade, o Banco de Dados Relacional teria uma performance melhor. Uma análise de performance foi realizada com o objetivo de verificar quanto tempo o Neo4J e o MySQL (RDBMS) levam para executar 2 tipos de consultas:
- Consulta Estrutural: realizar uma busca em largura nos dados até o quarto nível
- Consulta de Dados: contar o número de vértices/instâncias que têm um determinado atributos com o valor menor que um threshold
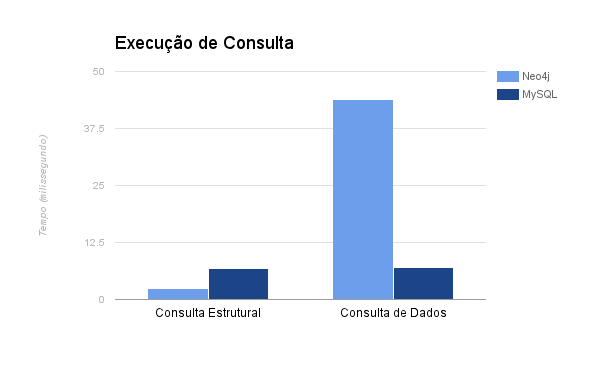
De acordo com os dados obtido durante o experimento, é possível perceber que o MySQL leva mais tempo para responder uma consulta estrutural em comparação ao Neo4J. Por outro lado, o Neo4J demorou mais para responder uma consulta de dados em relação ao MySQL.
Aplicações
Existem muitas áreas onde a utilização de Banco de Dados em Grafo é pertinente devido à natureza dos dados. Uma dessas áreas é Rede Sociais, como o exemplo mostrado ao longo deste post. Outra área importante é Bio-informática e Análise Genética, onde as interações entre moléculas e partículas são melhor representadas usando o modelo de dados em grafo. A área de Telecomunicações também utiliza banco de dados em grafo para armazenar informações sobre as ligações entre aparelhos e para analisar as áreas da rede que precisam de reforço da infra-estrutura (uma área onde ocorrem muitas ligações, por exemplo).
Além dessas áreas mais tradicionais, uma aplicação interessante de grafo é a análise da interação entre os personagens do livro “A Tormenta das Espadas”, o terceiro livro da série das Crônicas de Gelo e Fogo. Os matemáticos Andrew Beveridge e Jie Shan reuniram todas as interações entre os personagens do livro em um arquivo CSV com três colunas: personagem inicial, personagem final e o peso do relacionamento entre os dois. De posse desse arquivo, William Lyon carregou esses dados dentro no Neo4J e fez algumas análises interessantes sobre os núcleos e os personagens mais importantes da trama, gerando a visualização mostrada abaixo.
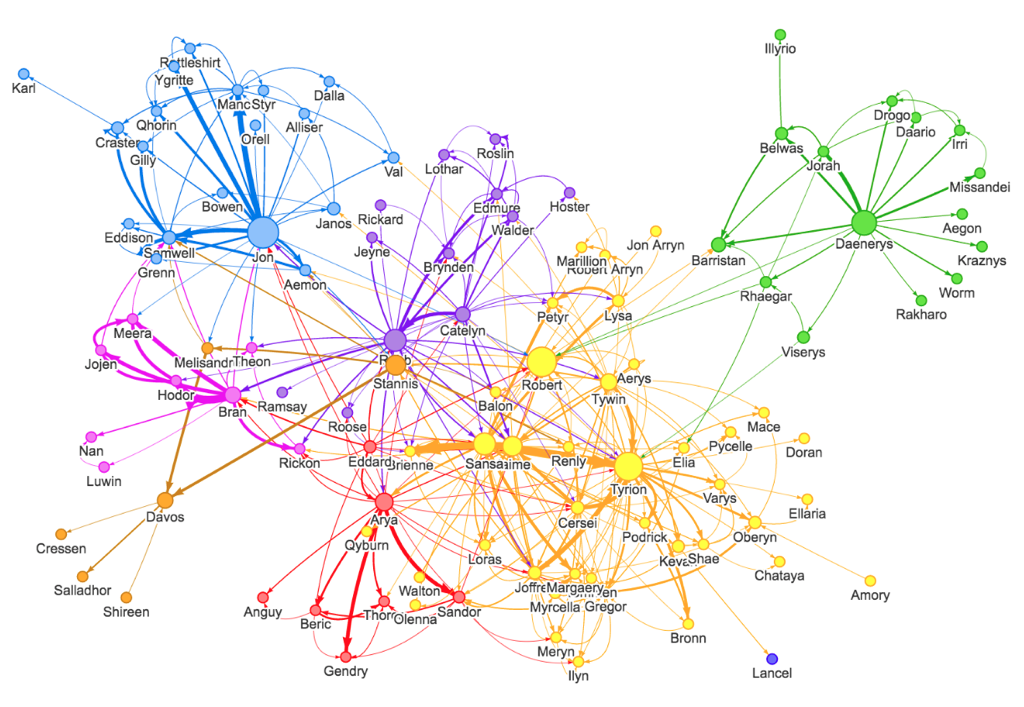
O diâmetro dos vértices é determinado pelo grau de intermediação do personagem, ou seja, a quantidade de “menores caminhos” entre dois outros vértices que passam pelo vértice do personagem em questão. Essa medida indica os personagens que transmitem informação entre os clusters. Para calcular o grau de intermediação (ou betweenness centrality, em inglês), Lyon utilizou a **biblioteca apoc**, que contém um conjunto de procedimentos escritos em Java que podem ser chamados a partir de uma consulta Cypher. O código abaixo mostra como calcular a medida de intermediação para todos os personagens do banco.
Já as diferentes cores do grafo resultante correspondem aos diferentes núcleos de personagens da trama. Para identificar esses núcleos, Lyon utilizou o módulo iGraph de Python que permite a manipulação de grafo e implementa o algoritmo de detecção de comunidades. O código abaixo mostra como iGraph pode ser usado para identificar os núcleos de personagens.
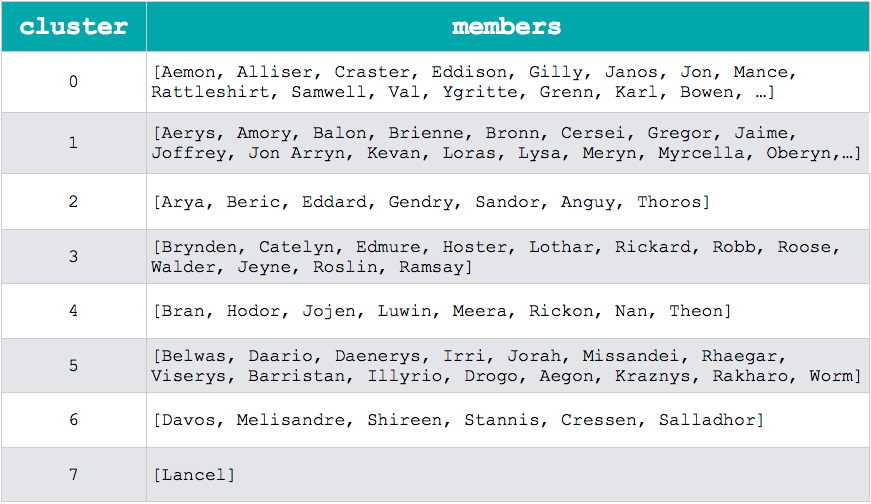
Inicialmente, o vértices e relacionamentos que estão armazenado no Neo4J são carregados para o grafo virtual do iGraph. Em seguida, as comunidades são detectadas através do método community_walktrap e cada vértice passa a possuir um novo atributo indicando a qual comunidade ele pertence. Finalmente, essa nova informação é armazenada novamente no Neo4J. A tabela abaixo mostra a saída do algoritmo de detecção de comunidade executado pelo iGraph.
O trabalho de Lyon é um bom exemplo dos tipos de análises que é possível fazer em um Banco de Dados de Grafo. A partir dessa análise, consegue-se extrair novos conhecimentos acerca dos principais personagens da trama e de como eles se relacionam com os demais. No artigo original, Lyon também mostra outras medidas e outros algoritmos relacionados à análise em grafo.
Análise e extração de conhecimento são conceitos que remetem à estruturas de grafo e armazenar dados em BDs que facilitam a execução dessas atividades pode ser uma grande ajuda para a aplicação em questão. Para aprender mais sobre BDs em grafo, seguem alguns links interessantes:
